Spoken Language Processing Research Lab


SLP Research Lab
The School of Computer Science and Engineering The Hebrew University of JerusalemThe Spoken Language Processing Research Lab (SLP-RL), led by Dr. Yossi Adi at The Hebrew University of Jerusalem, is a dynamic hub for cutting-edge research. Our diverse research interests span spoken language modeling, automatic speech recognition, speech enhancement, speech and audio generation, and machine learning for audio, speech, and language processing.
Our lab collaborates with the global research community to advance speech technology through machine learning and deep learning toolks. Our goal is to create adaptive systems that enrich spoken human communication across various languages.
If you would like to pursue graduate studies with us (Master or PhD), please send your CV, research interests, and example code projects to the following address: yossi.adi@mail.huji.ac.il.
News
- Two research papers got accepted to ACL 2026! More details in the publication section.
- Three research papers got accepted to ICASSP 2026! More details in the publication section.
- We are co-organizing a challenge to ICASSP 2026 on Low-Resource Audio Codec (LRAC)!
- Our research paper GmSLM : Generative Marmoset Spoken Language Modeling got accepted to EMNLP (Findings) 2025!
- Two research papers got accepted to ASRU 2025! More details in the publication section.
- Our research paper Scaling Analysis of Interleaved Speech-Text Language Models got accepted to COLM 2025!
- Our research paper CAFA: a Controllable Automatic Foley Artist got accepted to ICCV 2025!
- Together with Joseph Keshet I am organizing iSpeech-2025, the second Israeli seminar on Speech & Audio processing using neural nets.
- Two research papers got accepted to INTERSPEECH 2025! More details in the publication section.
- Our research paper Slamming: Training a Speech Language Model on One GPU in a Day got accepted to ACL (Findings) 2025!
- Four research papers got accepted to ICASSP 2025! More details in the publication section.
- Two research papers got accepted to ISMIR 2024! More details in the publication section.
- Five research papers got accepted to Interspeech 2024! More details in the publication section.
- We are co-organizing a tutorial to Interspeech 2024 on Recent Advances in Speech Language Models!
- We are co-organizing two special sessions to Interspeech 2024 on SpeechLMs and Discrete speech representation for speech processing!
- Our research paper Masked Audio Generation using a Single Non-Autoregressive Transformer got accepted at ICLR 2024!
- Two research papers got accepted to AAAI 2024! More details in the publication section.
- Two research papers got accepted at EMNLP 2023!
- Four research papers got accepted at NeurIPS 2023!
- Two research papers got accepted at Interspeech 2023!
- Our research paper ReVISE: Self-Supervised Speech Resynthesis with Visual Input for Universal and Generalized Speech Enhancement was accepted at CVPR 2023!
- Five research papers got accepted to ICASSP 2023!
- We started a New PhD program between HUJI and FAIR, Meta AI.
- Our research paper AudioGen: Textually Guided Audio Generation was accepted at ICLR 2023!
- Our research paper On the Importance of Gradient Norm in PAC-Bayesian Bounds was accepted at NeurIPS 2022!
- Our research paper RemixIT: Continual Self-Training of Speech Enhancement Models via Bootstrapped Remixing was accepted at IEEE JSTSP.
- Five research papers got accepted to Interspeech 2022!
Members
Faculty

Ph.D. Students



(co-advising with Shmuel Peleg)


Alumni
- P.hD. Michael Hassid (Meta)
- M.Sc. Aaron Taub (Apple)
- Ph.D. Robin San Roman (Meta)
- M.Sc. Yuval Ringel (Microsoft)
- M.Sc. Talia Sternberg
- M.Sc. Mickey Finkelson, (Lightricks)
- M.Sc. Dor Tenenboim, (Meta)
- M.Sc. Avishai Elmakies, (IBM)
- M.Sc. Yair Shemer, (MobileEye)
- M.Sc. Nadav Har-Tuv, (MobileEye)
- M.Sc. Shoval Messica, (Mentee Robotics)
- M.Sc. Ella Zeldes
- M.Sc. Amit Roth
- M.Sc. Roy Sheffer, (MobileEye)
- M.Sc. Amitay Sicherman, (Google)
- M.Sc. Avi Rosen (Snap Inc.)
- M.Sc. Moshe Mandel
Textless NLP
In TextlessNLP, our goal is to build large language models that can directly process audio inputs, without accessing any textual supervision. Being able to achieve that would benefit languages that do not have large textual resources or standard orthography. It would also benefit high-resource languages where: (i) the oral and written forms often mismatch; (ii) linguistically relevant signals are absent from text (e.g., intonation)
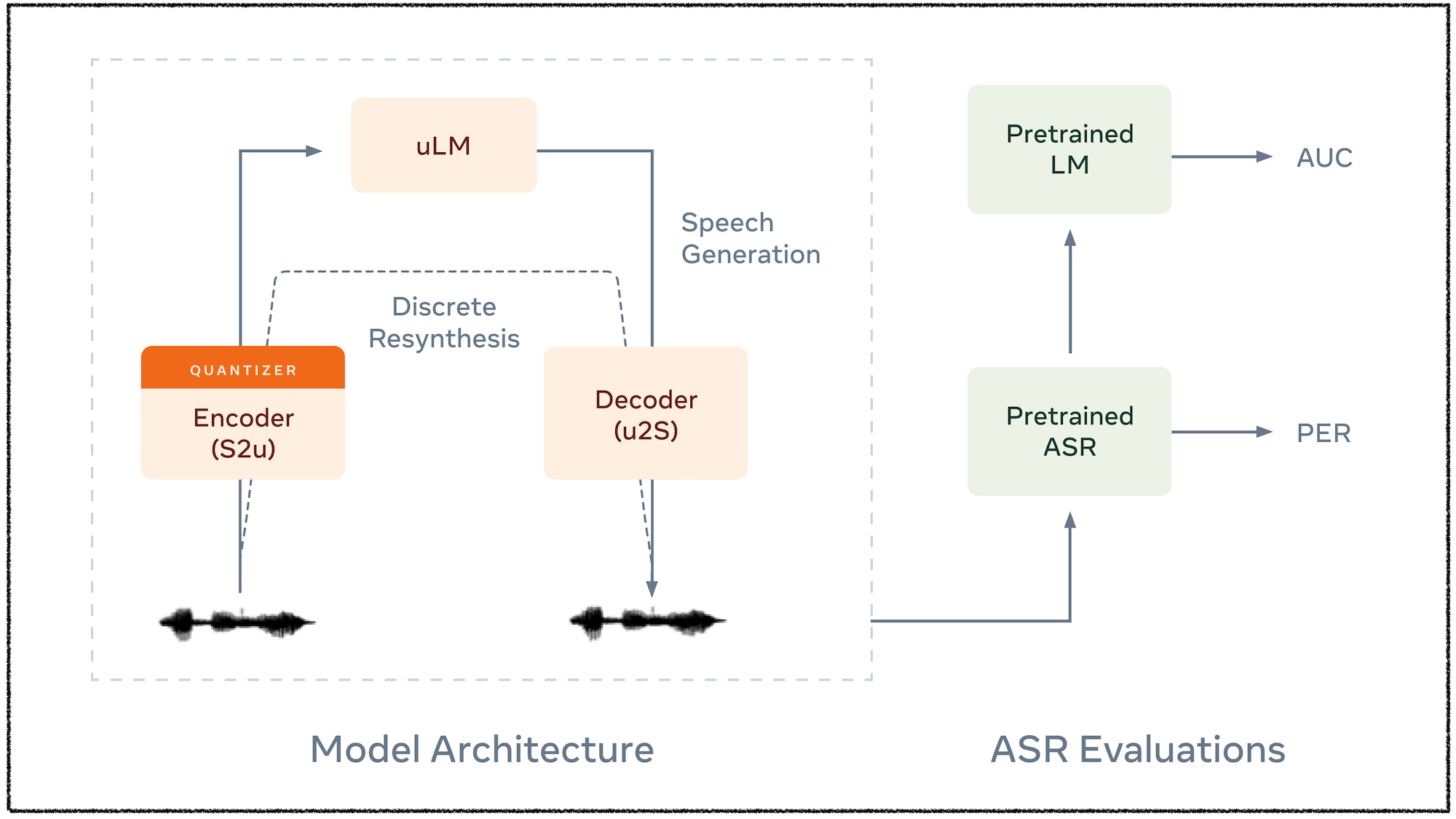
Audio Research
The SLP Research Lab is actively involved in conducting research and advancing neural architectures to address various fundamental challenges in the domain of audio processing. This encompasses a wide range of tasks, including background noise removal, artificial bandwidth-extension (a.k.a audio super-resolution), audio compression, voice conversion, etc. For additional details, please refer to the publication section.
Hebrew Speech Technologies
Speech technology has made much progress over the past decade and has been integrated into many consumer products. Despite the progress, most of the models were developed for English and other high-resource languages. In this project, our goal is to build speech technologies (automatic-speech-recognition and text-to-speech) for the Hebrew language together with constructing a large scale Hebrew dataset.

Selected Publications
Here is a list of selected publications from our group. For the full list of publications see my Google Scholar.
2026
- . DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion. The 43rd International Conference on Machine Learning (ICML), 2026 [PDF, Project page].
- . StressTest: Can YOUR Speech LM Handle the Stress?. Findings of The 64th Annual Meeting of the Association for Computational Linguistics (ACL), 2026 [PDF, Project page].
- . LaMI: Augmenting Large Language Models via Late Multi-Image Fusion. The 64th Annual Meeting of the Association for Computational Linguistics (ACL), 2026 [PDF, Project page, Code].
- . Low-Resource Audio Codec (LRAC): 2025 Challenge Description. The 51st IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2026 [PDF].
- . MR-FLOWDPO: Multi-Reward Direct Preference Optimization for Flow-Matching Text-to-Music Generation. The 51st IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2026 [PDF, Project page].
- . T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS. The 51st IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2026 [PDF].
- . Post-training is (Massive) Supervised Learning. openreview, pdf-id: 7P1VeDIY5, (2026) [PDF].
- . Self-Execution Simulation Improves Coding Models. arXiv preprint arXiv:2604.03253 (2026) [PDF].
2025
- . GmSLM : Generative Marmoset Spoken Language Modeling. Findings of Empirical Methods in Natural Language Processing (EMNLP), 2025 [PDF].
- . Speech Synthesis From Continuous Features Using Per-Token Latent Diffusion. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2025 [PDF].
- . Benchmarking Fast Domain Adaptation for Unsupervised Speech Units. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2025.
- . Scaling Analysis of Interleaved Speech-Text Language Models. The 2nd Conference on Language Modeling (COLM), 2025 [PDF, Project page].
- . CAFA: a Controllable Automatic Foley Artist. The IEEE/CVF International Conference on Computer Vision (ICCV), 2025 [PDF, Project page].
- . WHISTRESS: Enriching Transcriptions with Sentence Stress Detection. The 26th Annual Conference of the International Speech Communication Association (Interspeech), 2025 [PDF, Project page].
- . PAST: Phonetic-Acoustic Speech Tokenizer. The 26th Annual Conference of the International Speech Communication Association (Interspeech), 2025 [PDF, Project page].
- . Slamming: Training a Speech Language Model on One GPU in a Day. Findings of The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025 [PDF, Project page].
- . Through-The-Mask: Mask-based Motion Trajectories for Image-to-Video Generation. The Conference on Computer Vision and Pattern Recognition (CVPR), 2025 [PDF, Project page].
- . A Suite for Acoustic Language Model Evaluation. The 50th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2025 [PDF, Code & Data].
- . Enhancing TTS Stability in Hebrew using Discrete Semantic Units. The 50th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2025 [PDF, Code & Demo].
- . Latent Watermarking of Audio Generative Models. The 50th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2025 [PDF].
- . MusicGen-Stem: Multi-stem music generation and edition through autoregressive modeling. The 50th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2025 [PDF].
2024
- . Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation. The 25th International Society for Music Information Retrieval (ISMIR) Conference, (2024) [PDF].
- . Audio Conditioning for Music Generation via Discrete Bottleneck Features. The 25th International Society for Music Information Retrieval (ISMIR) Conference, (2024) [PDF].
- . NAST: Noise Aware Speech Tokenization for Speech Language Models. The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024 [PDF, Code].
- . The Interspeech 2024 Challenge on Speech Processing Using Discrete Units. The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024 [PDF].
- . Audio Enhancement from Multiple Crowdsourced Recordings: A Simple and Effective Baseline. The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024 [PDF].
- . A Language Modeling Approach to Diacritic-Free Hebrew TTS. The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024 [PDF, Code].
- . HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing. The 25th Annual Conference of the International Speech Communication Association (Interspeech), 2024 [PDF, Data].
- . An Independence-promoting Loss for Music Generation with Language Models. The 41st International Conference on Machine Learning (ICML), 2024 [PDF].
- . Masked Audio Generation using a Single Non-Autoregressive Transformer. International Conference on Learning Representations (ICLR), 2024 [PDF, Code & Samples].
- . Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation. The Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI), 2024 [PDF, Code & Samples].
2023
- . Generative Spoken Language Model Based on Continuous Word-sized Audio Tokens. Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 [PDF].
- . Speaking Style Conversion With Discrete Self-Supervised Units. Findings of Empirical Methods in Natural Language Processing (EMNLP), 2023 [PDF, Code & Samples].
- . Textually Pretrained Speech Language Models. The 37th Annual Conference on Neural Information Processing Systems (NeurIPS), 2023 [PDF, Samples].
- . From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion. The 37th Annual Conference on Neural Information Processing Systems (NeurIPS), 2023 [PDF, Code, Samples].
- . Simple and Controllable Music Generation. The 37th Annual Conference on Neural Information Processing Systems (NeurIPS), 2023 [PDF, Code, Samples, Demo].
- . Adaptation of Text-Conditioned Diffusion Models for Audio-to-Image Generation. The 24th Annual Conference of the International Speech Communication Association (Interspeech), 2023 [PDF, Code, Demo, Samples].
- . Expresso: A Benchmark and Analysis of Discrete Expressive Speech Resynthesis. The 24th Annual Conference of the International Speech Communication Association (Interspeech), 2023 [PDF, Data].
- . ReVISE: Self-Supervised Speech Resynthesis with Visual Input for Universal and Generalized Speech Enhancement. The Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [PDF, Samples].
- . AERO: Audio Super Resolution in the Spectral Domain. The 48th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2023 [PDF, Code, Samples].
- . I Hear Your True Colors: Image Guided Audio Generation. The 48th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2023 [PDF, Code, Samples].
- . Analyzing Discrete Self Supervised Speech Representation For Spoken Language Modeling. The 48th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2023 [PDF, Code, Tool].
- . AudioGen: Textually Guided Audio Generation. International Conference on Learning Representations (ICLR), 2023 [PDF, Samples].
2022
- . Deep Audio Waveform Prior. The 23rd Annual Conference of the International Speech Communication Association (Interspeech), 2022 [PDF].
- . A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement. The 23rd Annual Conference of the International Speech Communication Association (Interspeech), 2022 [PDF, Code].
- . Unsupervised Symbolic Music Segmentation using Ensemble Temporal Prediction Errors. The 23rd Annual Conference of the International Speech Communication Association (Interspeech), 2022 [PDF].
- . Continual Self-Training with Bootstrapped Remixing For Speech Enhancement. The 47th IEEE International Conference in Acoustic, Speech and Signal Processing (ICASSP), 2022 [PDF].
- . RemixIT: Continual Self-Training of Speech Enhancement Models via Bootstrapped Remixing. IEEE Journal of Selected Topics in Signal Processing, 2022 [PDF].
2021
- . Fairness in the Eyes of the Data: Certifying Machine-Learning Models. The Forth AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES), 2021 [PDF].
Open-source
At our laboratory, we are dedicated to open source and open research principles. All our source code and pre-trained models are publicly available, and we actively gather diverse spoken datasets in multiple languages for training and evaluating speech technologies. With embracing openness, our aim is to drive innovation and collaboration in the field of speech technology globally.
Code & Datasets
All source-code, pre-trained models and datasets are available under the SLP Research Lab GitHub page and HuggingFace page.
