
iSpeech 2023 is the first Israeli seminar on Speech & Audio processing using neural nets. It is a venue for presenting the most recent work on the science and technology of spoken language processing both in academia and industry. Our goal is to bring the research community together to exchange ideas, form collaborations, and present their latest research work.
This year, we will have two keynote speakers: Shinji Watanabe (CMU) and Gabriel Synnaeve (FAIR), together with additional talks and presentations from researchers and students from the local Israeli ecosystem.
We encourage researchers and students to submit their work for presentation at the conference. We will consider: (i) accepted papers from the past year (both journal and conference publications); (ii) a single-page (extended abstract) presenting preliminary results of promising research directions.
Notice, the conference will be live streamed under the following link.
- The conference will take place at the Computer Science Auditorium, Building A, Rothberg Building.
- There is no parking inside the campus. We encourage the participants to use public transportation.
- Click here for Google Maps directions.
- Click here for Waze directions.
- Click here for pedestrian directions.
Important Dates
- Papers submission open: April 5th, 2023.
- Papers submission deadline: May 4th, 2023.
- Papers acceptance notification: May 24th, 2023.
- Conference date: June 15th, 2023.
Conference Program
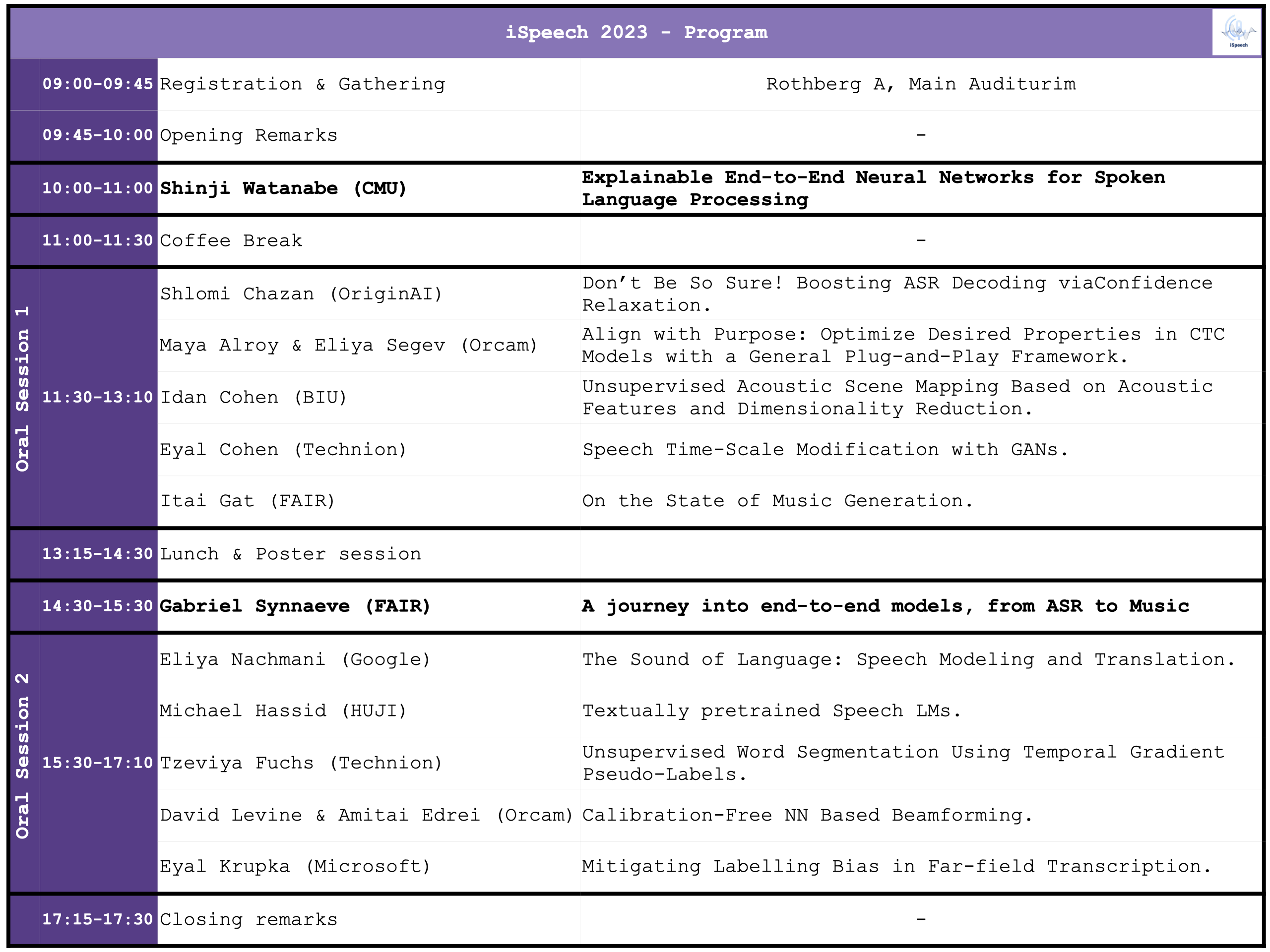
Keynote speakers
Speaker: Shinji Watanabe (CMU).
Title: Explainable End-to-End Neural Networks for Spoken Language Processing.
Abstract: This presentation will showcase our group's efforts to integrate various spoken language processing modules into a single end-to-end neural network. Our focus will be on far-field conversation recognition, and we will demonstrate how we have successfully united automatic speech recognition, denoising, dereverberation, separation, and localization while maintaining explainability. By utilizing self-supervised learning, pre-training/fine-tuning strategies, and multi-task learning within our integrated network, we have achieved the best performance reported in the literature on several noisy reverberant speech recognition benchmarks, even reaching clean speech recognition performance. Additionally, we will provide other examples demonstrating the integration of automatic speech recognition with machine translation and natural language understanding for spoken language understanding and speech translation tasks. Our code and models are publicly available through the ESPnet toolkit, which can be accessed at https://github.com/espnet/espnet.
Speaker: Gabriel Synnaeve (FAIR).
Title: A journey into end-to-end models, from ASR to Music.
Conference Details
Details
- Where: iSpeech 2023 will be held at the Hebrew University (Givat Ram Campus).
- Computer Science Auditorium, Building A, Rothberg Building.
- There is no parking inside the campus. We encourage the participants to use public transportation.
- Click here for Google Maps directions.
- Click here for Waze directions.
- Click here for pedestrian directions.
- Where: iSpeech 2023 will be held at the Hebrew University (Givat Ram Campus).
- When: June 15, 2023.
- How: Registration is free of charge. Registration is over.
- Submission: Papers should be submitted to: ispeech2023@gmail.com.
Conference committee
- Yossi Adi (HUJI)
- Joseph Keshet (Technion)
- Tal Rosenwein (Orcam)
- Irit Opher (Verbit)
- Israel Cohen (Technion)
- Felix Kreuk (FAIR - MetaAI)
- Michelle Tadmor Ramanovich (Google)
Organizers
- Yossi Adi (HUJI)
- Joseph Keshet (Technion)
- Tal Rosenwein (Orcam)
FAQ
- Q: Is iSpeech 2023 seminar archival?
- A: No. Works presented at iSpeech 2023 will not be considered as archived and therefore can be published elsewhere.
- Q: Can I submit a paper that was published or accepted to be published in another venue?
- A: Yes. If it was accepted (to be) published during this year.
- Q: Can I submit a full paper instead of an extended abstract?
- A: Yes! if it was submitted in a related venue as a full paper. Please indicate whether the paper was accepted (and venue), rejected, or is currently under review.
- Q: Submission file format and style.
- A: You should submit a PDF file. We are not petty about the style.
- Q: Do I need to print my poster?
- A: Yes. You will have to print your own posters, hang it in the break before your poster session and take it down during the break following your poster session.
- Q: What are the dimensions for the posters?
- A: The poster stands are 90cm wide and 120cm tall so your poster shouldn't be bigger than that. Make sure the posters (and the fonts) are not too small so participants can gather around while still allowing some space.
- Q: Should I present in English?
- A: Yes.

