The MAPS Framework
Develop optimized GPU and multi-GPU applications using Memory Access Pattern Specification
MAPS is an open-source, header-only C++ CUDA template library for automatic multi-GPU programming and optimization of GPU kernels.
The framework leverages memory access patterns to provide near-optimal performance on various architectures.
Using MAPS:
The framework leverages memory access patterns to provide near-optimal performance on various architectures.
Using MAPS:
- - Automatically produces optimized GPU code
- - Separates complex indexing and shared memory optimizations from the algorithm
- - Transparently manages multi-GPU memory segmentation and inter-GPU communication
- - Provides familiar STL-based interfaces (containers and iterators)
- - Results in short, intelligible code
Example
The following kernel performs a highly optimized two dimensional 9x9 (radius 4) convolution on multiple GPUs:
__global__ void Conv2(const float *in, int width, int height, int stride,
const float *convKernel, float *out) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float result = 0.0f;
for (int ky = -4; ky <= 4; ++ky) {
for (int kx = -4; kx <= 4; ++kx) {
result += in[CLAMP(y + ky, 0, height) * stride + CLAMP(x + kx, 0, width)] *
convKernel[(ky + 4) * 9 + (kx + 4)];
}
}
out[y * stride + x] = result;
}__constant__ float kConvKernel[9*9];
__global__ void Conv2 MAPS_MULTIDEF(maps::Window2D<float, BLOCK_WIDTH, BLOCK_HEIGHT, RADIUS> in,
maps::StructuredInjective2D<float, BLOCK_WIDTH, BLOCK_HEIGHT> out) {
MAPS_MULTI_INITVARS(in, out); // Initialize multi-GPU abstraction and containers
MAPS_FOREACH(oiter, out) { // Loop over output elements
int i = 0;
*oiter = 0.0f;
MAPS_FOREACH_ALIGNED(iter, in, oiter) { // For each output, loop over inputs according to pattern
*oiter += *iter * kConvKernel[i++];
}
}
out.commit(); // Write all outputs to global memory
}__constant__ float kConvKernel[9*9];
__global__ void Conv2(const float *in, int width, int height, int stride,
float *out) {
int x = blockIdx.x * BLOCK_WIDTH;
int y = blockIdx.y * BLOCK_HEIGHT;
enum
{
BLOCK_STRIDE = (BLOCK_WIDTH + 8),
};
__shared__ float s_temp[(BLOCK_WIDTH + 8) * (BLOCK_HEIGHT + 8)];
s_temp[BLOCK_STRIDE * threadIdx.y + threadIdx.x] = in[CLAMP(y + threadIdx.y - 4, 0, height) * stride +
CLAMP(x + threadIdx.x - 4, 0, width)];
if (threadIdx.x < 8) {
s_temp[BLOCK_STRIDE * threadIdx.y +
threadIdx.x + BLOCK_WIDTH] = in[CLAMP(y + threadIdx.y - 4, 0, height) * stride +
CLAMP(x + threadIdx.x + BLOCK_WIDTH, 0, width)];
}
if (threadIdx.y < 8) {
s_temp[BLOCK_STRIDE * (threadIdx.y + BLOCK_HEIGHT) +
threadIdx.x] = in[CLAMP(y + threadIdx.y + BLOCK_HEIGHT, 0, height) * stride +
CLAMP(x + threadIdx.x - 4, 0, width)];
}
if (threadIdx.x < 8 && threadIdx.y < 8) {
s_temp[BLOCK_STRIDE * (threadIdx.y + BLOCK_HEIGHT) +
threadIdx.x + BLOCK_WIDTH] = in[CLAMP(y + threadIdx.y + BLOCK_HEIGHT, 0, height) * stride +
CLAMP(x + threadIdx.x + BLOCK_WIDTH, 0, width)];
}
__syncthreads();
float result = 0.0f;
#pragma unroll
for (int ky = 0; ky < 9; ++ky) {
#pragma unroll
for (int kx = 0; kx < 9; ++kx) {
result += s_temp[BLOCK_STRIDE * (threadIdx.y + ky) +
(threadIdx.x + kx)] * kConvKernel[ky * 9 + kx];
}
}
out[(y+threadIdx.y) * stride + (x+threadIdx.x)] = result;
}For more examples, see the Showcase.
Performance
The performance of the convolution kernels is shown below: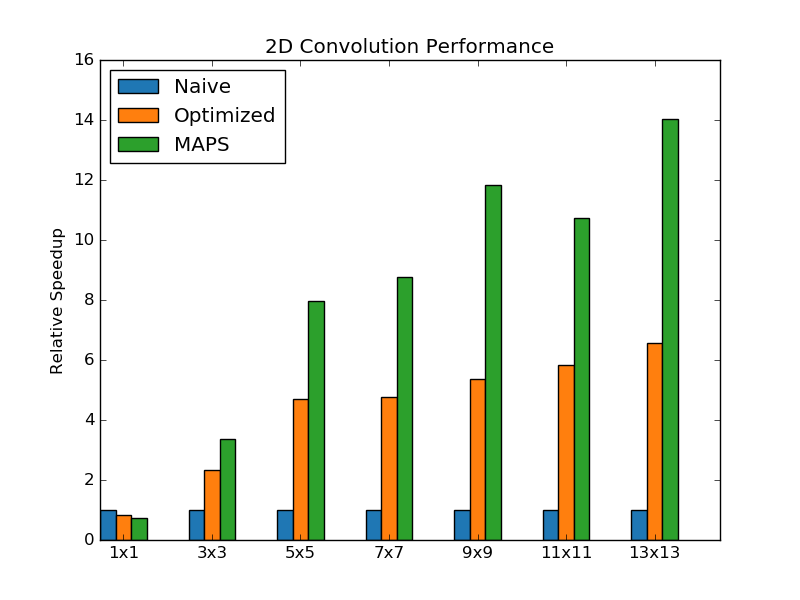
For more results, see the Performance page.
Publications
- Memory Access Patterns: The Missing Piece of the Multi-GPU Puzzle (slides)
Tal Ben-Nun, Ely Levy, Amnon Barak and Eri Rubin
In IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Analysis (SC15), 2015. - MAPS: Optimizing Massively Parallel Applications Using
Device-Level Memory Abstraction
Eri Rubin, Ely Levy, Amnon Barak and Tal Ben-Nun
In ACM Transactions on Architecture and Code Optimization (TACO), 2014.
Cite us:
@inproceedings{maps-multi,
author = {Ben-Nun, Tal and Levy, Ely and Barak, Amnon and Rubin, Eri},
title = {Memory Access Patterns: The Missing Piece of the Multi-{GPU} Puzzle},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
series = {SC '15},
isbn = {978-1-4503-3723-6},
location = {Austin, Texas},
pages = {19:1--19:12},
articleno = {19},
numpages = {12},
doi = {10.1145/2807591.2807611},
acmid = {2807611},
year = {2015},
publisher = {ACM},
}