Abstract
High dynamic range (HDR) photography is becoming increasingly popular and available by DSLR and mobile-phone cameras. While deep neural networks (DNN) have greatly impacted other domains of image manipulation, their use for HDR tone-mapping is limited due to the lack of a definite notion of ground-truth solution, which is needed for producing training data. In this paper we describe a new tone-mapping approach guided by the distinct goal of producing low dynamic range (LDR) renditions that best reproduce the visual characteristics of native LDR images. This goal enables the use of an unpaired adversarial training based on unrelated sets of HDR and LDR images, both of which are widely available and easy to acquire. In order to achieve an effective training under this minimal requirements, we introduce the following new steps and components: (i) a range-normalizing pre-process which estimates and applies a different level of curve-based compression, (ii) a loss that preserves the input content while allowing the network to achieve its goal, and (iii) the use of a more concise discriminator network, designed to promote the reproduction of low-level attributes native LDR possess. Evaluation of the resulting network demonstrates its ability to produce photo-realistic artifact-free tone-mapped images, and state-of-the-art performance on different image fidelity indices and visual distances.Paper
A preprint is available on Arxiv.
Code is available on GitHub.
For additional results check out our Supplementary Material.
 Tone-mapped HDR images produced by our method.
The four exposures on the bottom of each image portray the very highdynamic range in the original scenes
Tone-mapped HDR images produced by our method.
The four exposures on the bottom of each image portray the very highdynamic range in the original scenes
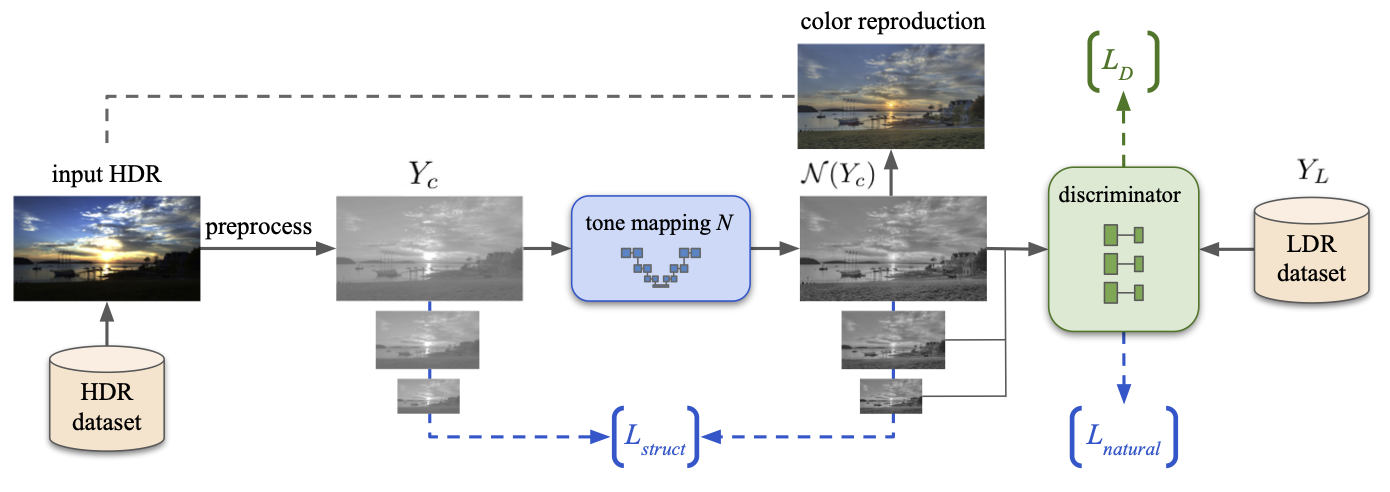 Tone-Mapping Pipeline. Given an input HDR image, we estimate the level of compression needed for mapping its luminance into a fixed-range map, Yc. The latter is fed to the tone mapping network N as well as used for defining the structure-preservation loss. The network is also trained to minimize an adversarial loss with respect to native LDR images. The final output image is produced from the resulting luma, N(Yc), and the chromaticity of the input image. We mark in blue and green the components that participate in the training of the network N and D respectively.
Tone-Mapping Pipeline. Given an input HDR image, we estimate the level of compression needed for mapping its luminance into a fixed-range map, Yc. The latter is fed to the tone mapping network N as well as used for defining the structure-preservation loss. The network is also trained to minimize an adversarial loss with respect to native LDR images. The final output image is produced from the resulting luma, N(Yc), and the chromaticity of the input image. We mark in blue and green the components that participate in the training of the network N and D respectively.